






About Us
Trusted to provide high-quality structured data and performance insights, Spidey Scrape is the superstar software squad to hit up when the going gets tough. We are the kings of the data industry and will help you become champion of the data you use and need.
- CEOs spend almost 20% of their time on work that could be automated.
- Good data allows organizations to establish baselines, benchmarks, and goals to keep moving forward.
- Data will help you to improve quality of life for people you support.
We help organizations of all magnitudes implement solutions and further develop their data structures so as to more accurately and efficiently produce the results they desire. The data cosmos can be treacherous to maneuver through, but you don't have to do it alone- it is never a problem to ask for a helping hand. Spidey Scrape is always here to pick you up when you fall... and to make sure that you don't fall again.
Get Quote
Satisfied Clients who can't get enough of our superstar services.
Projects completed on behalf of our world-class character clients.
Years of Experience averaged among our team of dedicated data developers.
Months on average saved when employing our data automation and analysis services.
Quick Facts
What is Web Scraping?
Web scraping refers to the extraction of data from a website. This information is collected and then exported into a format that is more useful for the user, whether it be a spreadsheet or a database.
In general, web scraping is used by people and businesses who want to make use of the vast amount of publicly available web data to make smarter decisions.
Web scraping acts as a gateway to incorporating other practices, such as data analytics, data mining, and predictive forecasting. What good is your data if you don't analyze and apply it?
Why Web Scrape?
There are no two phrases that companies love more than "increased revenue" and "lower costs". Web scraping can easily accomplish both of these objectives.
Instead of hiring a team of data entry clerks to manually surf the web and input data, you can hire us to get the job done in a fraction of the time and cost.
Our clients have saved themselves, on average, approximately eight months of work and have been able to cut their project's budget by roughly 73%. They have also obtained access to data that they thought was previously untouchable.
How Can You Web Scrape?
Web scraping is a craft that often takes years to master. But just because you can't master it now doesn't mean you can't take advantage of its benefits. Contact Spidey Scrape today so that we can give you a fair quote.
Speed
Cost-Effective
Performance Reliability
Efficient
Extraction at Scale
Increased Productivity
Low Maintenance
Accurate
Services
Plenty of unique and interconnected services to help your organization achieve its data goals.

Web Scraping
Extract information found on the internet into clean, structured, and readable data-formatted files. Useful for lead generation, eCommerce price monitoring, social media trends, real estate, et cetera. XLSX, CSV, XML, JSON

Web Crawling
Map websites and gather URLs so that web scraping bots can be pointed to specific webpages. Collect all the email addresses and phone numbers listed on the webpages of those websites crawled and mapped. Googlebot is an example of one large web crawler that we interact with on a daily basis- it indexes webpages based on keyword searches.
Web Browser Automation
Automate a repetitive and tedious web task. Logging into an admin console. Sending out emails everyday at a specific time. Purchasing products on an interval basis. Navigating through a website. Copying and pasting information. Filling in web forms. Extract source code from websites with greater security measures, of which include anti-scraping bots.
Task Automation
Also known as robotic process automation (RPA), task automation helps expedite the monotony of uninteresting and manual tasks. Schedule appointments. Process claims and automate procedural billing duties. Conduct automated reporting for organizational insight. Fetch data from other platforms. Move files and folders.
Descriptive Analytics
What happened? Simplify large amounts of data in a sensible way. Summarize data in the form of elementary statistical measures. Identify trends and relationships that cannot be otherwise observed by eye-balling the data. Visually display information to more comprehensively make connections and kickstart the decision-making process. Business intelligence is a subset of this practice.

Diagnostic Analytics
Why did this happen? Use data to determine the causes of trends and correlations between variables. Uncover the reasoning behind certain results. Transition from knowing about the problem to understanding the root of the problem. It is better to recognize how to react to the ongoing issue rather than simply acknowledging its presence and doing nothing. Business anaylytics is a subset of this practice.
Predictive Analytics
What is likely going to happen? Be proactive, not reactive. Acknowledging instances of potential vulnerability are essential for an organization's success. Use historical data patterns to determine if those patterns are likely to emerge again. Employ statistical methods and modeling techniques to determine future performance. Optimize the utilization of resources. Improve operational efficiencies and reduce risk. Machine Learning is a subset of this practice.
Prescriptive Analytics
What should be done? Use data to determine an optimal course of action. Yield valuable solutions that will help with the decision-making process. Assign value to certain products and/or services according to customer preferences. Implement automated remedies and solutions to adjust to the presence of anomalies and different scenarios. Customize advertisements according to the demographics of the target audience. Enhance the user experience of your client base.
APIs
Request custom scripts that pull data from external data sources with just a few lines of code. Allow ourselves to connect you to data that is continuously being changed or updated. Expedite the process of automated data delivery. Faster and more efficient than email data delivery. Access to data made easy for the user.

Document Extraction
Extract information from a set of standardized documents. Rental applications and agreements. Invoices and receipts. Contact directories. Credit memorandums. Transactional reports. PDF and TXT files are the most commonly extracted documents.

Database Management
Store data in a more efficient and safe manner. Transfer data stored in outdated platforms to more contemporary platforms. Sync locally stored databases to cloud databases. Update the architecture of databases to adhere to standard practices. Manipulate and control data to meet necessary conditions throughout the entire data lifecycle.

Email Verification
Verify whether your email list is still viable. Determine whether a domain's server is still up and running. Receive a color-coated breakdown of the email verification results. Obtain projected domain-specific email patterns.
The Process
We don't want to just provide you with a service . We want to help you understand how that service was provided.
-
1. Study Target Website
Establish the method in which to acquire the URLs of the web pages that need to be scraped.
Breakdown the security protocols of the website. Determine whether the site contains honeypot traps, captchas, IP blacklists, rate limits, TLS fingerprinting, and/or CSRF tokens.
Dictate whether the website is static or dynamic- simple requests may not be enough. Web browser automation is a principal component of web scraping. -
2. Crawl Site Map
Crawling is the process where a search engine tries to visit every page of your website via a bot. The bot thereby creates a map that allows for efficient navigation.
Collect all the URLs that will redirect the scraper to the web pages whose content needs to be extracted. Store URLs in a cloud database in the event that specific web pages needs to be scraped again. -
3. Deconstruct HTML
Identify the tags and attributes containing the data that is set to be scraped. Pinpoint discrepancies between the structures of all the webpages.
Use CTRL+F to more easily find the data sought in the HTML source code. Ensure that duplicates of specific tag instances does not exist. Employ tag-attribute combinations that pinpoint the exact location of the data sought out. -
4. Build Scraper Bot
Implement packages that best pull the source code of the target website. Make adjustments to the contents of the source code so that obstructions are limited. Institute measures that circumvent the anti-scraping security protocols of the target website.
Apply the deconstructed elements of the HTML to lines of code that properly dissect the information sought. Clean components of the information extracted from the tags. -
5. Plug Holes In Bot
Account for potential vulnerabilities in code that could lead to errors. Implement safeguards and exceptions so that those errors can be mitigated.
Ensure that the scraper returns only the specific data points requested. Abide by the rules of structural integrity to ensure that the code is fast, efficient, and reduces memory intake. -
6. Store & Clean Data
Store records in a cloud database to avoid data loss in the event of software corruption, computer viruses, hardware impairment, human error, or theft.
Clean the data to ensure that the client is not receiving unusable or littered data. This process includes removing duplicate or irrelevant records, amending structural errors, filtering unwanted outliers, handling missing data, and validating the reliability of the data. -
7. Transfer Data
Transfer the data into a user-friendly format. XLSX, CSV, and JSON are all examples of structured file types that are highly requested by clients. Custom scripts and APIs are also available for implementation if the data is continuously being updated, or necessitates it. -
8. Relevant Analysis
What good is data if it isn't analyzed? Spidey Scrape specializes in data analysis, data mining, and predictive forecasting, as well.
Gathering insights from the data collected is often more important than the actual extraction phase. Data with no application or purpose is almost as bad as throwing away food you didn't eat.
Industries
Web scraping is not a practice exclusive to one singular industry.
Lead Generation
eCommerce
Social Media
Banking & Finance
Auto Industry
Real Estate
Human Resources
Sports
Travel & Tourism
SEO
Engineering
Legal
Marketing & Sales
Academia
Information Technology
Journalism
Weather
Stocks & Crypto
Insurance
Food & Beverage
Portfolio
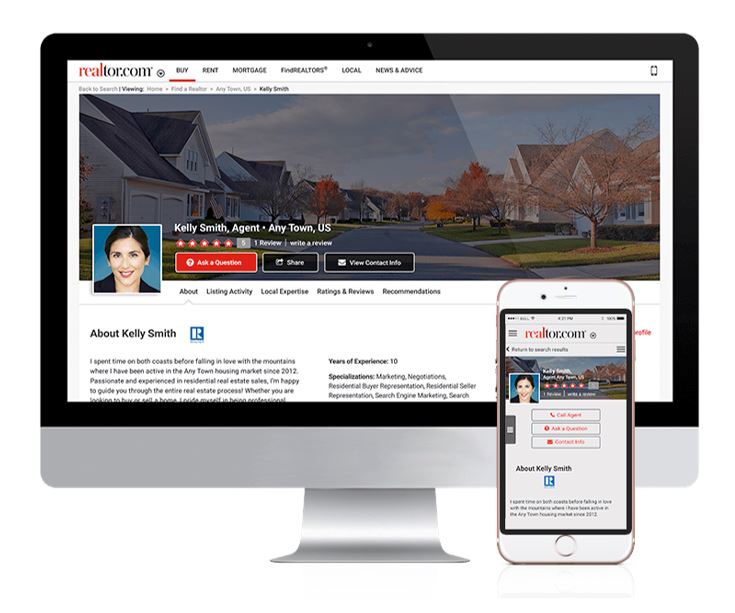
realtor.com Directory
With a projected membership of 1.6 million, realtors are a force to be reckoned with in the United States.
For those whose target business audience includes realtors, having a contact list is all but essential. Realtors
are always on their devices, so having a credible direct line of contact is important to forming a relationship with them.
Whether you're a mortgage broker, a property appraiser, or a digital marketer, ease of access to aggregate contact
information is crucial in determining the level of success in your realty endeavor.
Data Fields:
- First Name
- Last Name
- Personal Email
- Company Email
- Company
- Telephone
- Address
- Languages
- Specializations
- Areas Served
- Price Range
- Website
+ Web Crawling + Web Scraping
DFS Soccer Model
Since 2016, Daily Fantasy Sports (DFS) has been on meteoric rise to the top.
With a 2025 projected market capitalization of $39bn, DFS has become a staple of the sports industry.
Thousands upon thousands of players lock in their lineups every day in hopes of winning the pristined grand prizes.
Flocks of "esteemed" betting gurus take to Tik Tok to preach their "airtight" player predictions. And yet the average
DFS player will end up losing the majority of the time.
In a joint venture, Spidey Scrape and its partners decided to
test the DFS soccer environment by creating its very own predictive model. Ever since its inception, the model has witnessed a
27.3% return on investment, which is on par with the top 1.3% of all DFS players.
The number of variables is too great to
be listed in tabular format but they do encompass areas such as passing, shooting, dribbling, movement, defensive actions,
possession, team performance, injuries, player outlook, and streakiness.
+ Web Scraping + Data Analytics + Predictive Forecasting + Database Management + Data Consulting
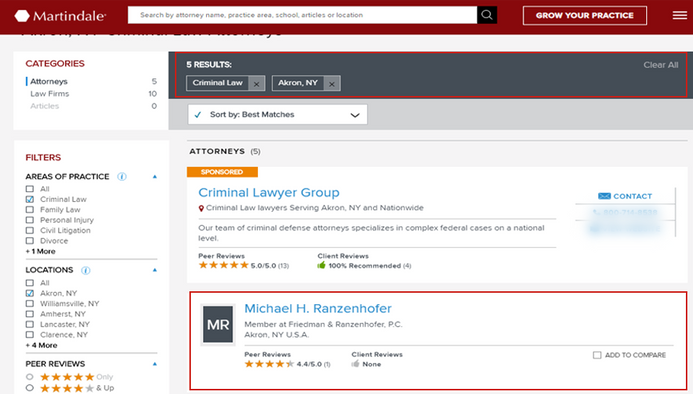
Martindale Law Directory
Martindale is among the most credible and comprehensive lawyer directories in the industry. It can turn a barren contact wasteland into one of detailed and dedicated potential. Lawyer lead generation has become one of the most popular undertakings in the web scraping world; and has correspondingly transitioned into vast corporate profits for those who take advantage of it.
Data Fields:
- Profile ID
- First Name
- Last Name
- Firm
- Website
- Telephone
- Address
- City
- State
- Zip Code
- Practice Areas
- Fax
- Law School
- Admission Year
- Jurisdictions
- Memberships
- Publications
- Client Rating
Although scraping Martindale yields a conglomeration of variables suitable for any marketing department to take advantage of, there is one key metric that is missing- email addresses.
Martindale prefers to keep this data point stored in its servers. This can be especially discouraging for clients who place a priority on the availability of emails.
However, given our expertise in web browser automation, we have created scripts that allow our clients to take advantage of the lawyer-specific contact forms on Martindale. So even without the email address, the client can still reach out via email.
ALL AUTOMATIC WITH NO SWEAT. Cross-referencing Martindale and other directories is also an option if the previous one does not suit your needs.
+ Web Crawling + Web Scraping + Web Browser Automation

Horticultural Shipping Cost Optimization
Projected to grow to approximately $2+ trillion by 2023, the world shipping industry is absolutely enormous. We rely on it to uphold the integrity of our international economy and get our burrito blankets on next day delivery.
Companies are the centerpiece of this industry. And as much as companies care about customers getting their burrito blankets on time, companies also care about maximizing profits.
Spidey Scrape
had the express pleasure of working with a well-renowed horticultural firm to optimize their shipping orders, ensuring that the highest amount of product was shipped out while also lowering costs. Our analytics team
was able to fill their containers with approximately 3.2% more product, thereby decreasing the overall number of shipments required.
It was a painstakingly grueling process that required our team to examine countless
factors and combinations, including but not limited to customer requests, plant types, distribution locations, hauling fees, freight costs, packaging methods, damage mitigation, and production delays.
+ Data Analytics
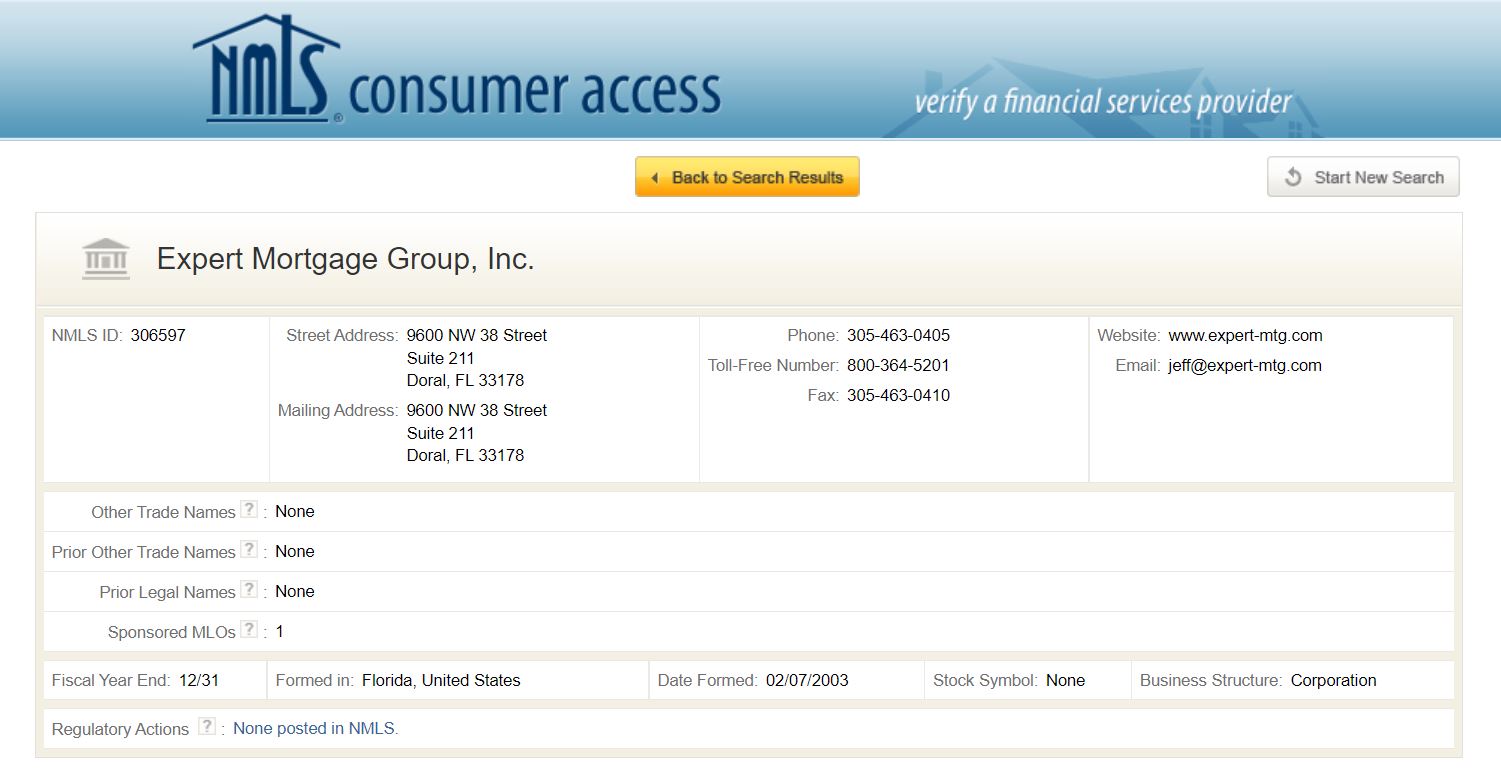
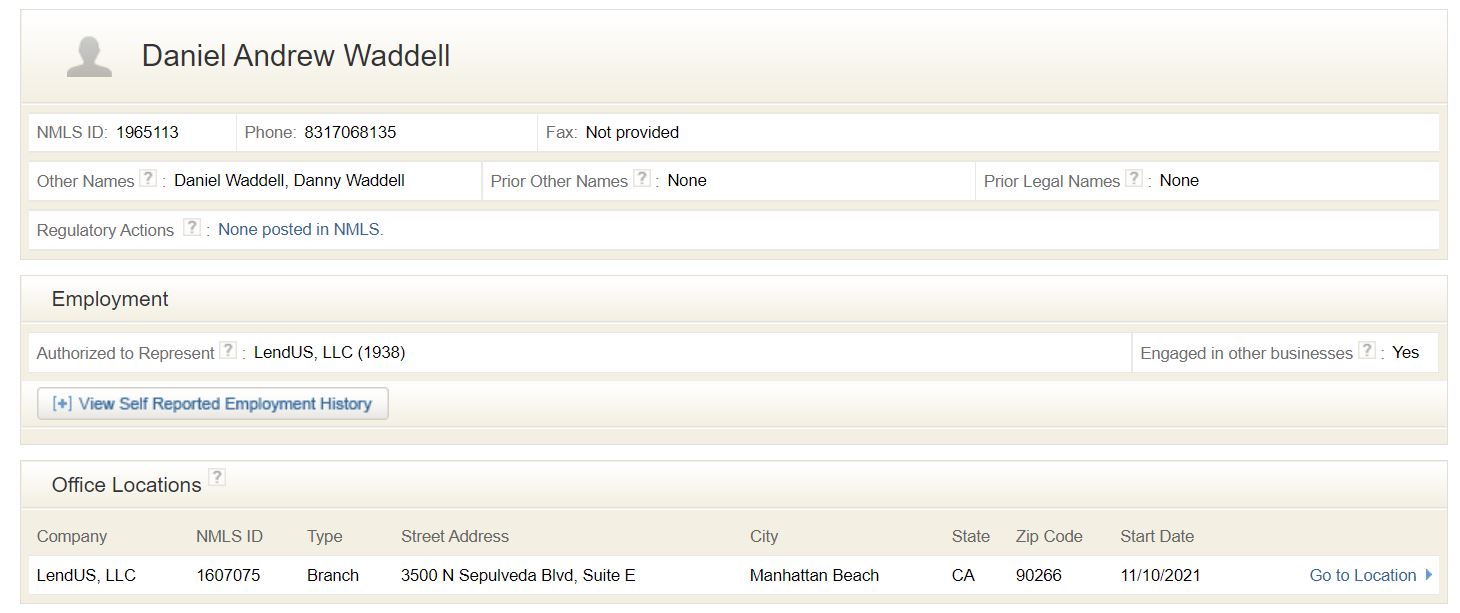
NMLS Consumer Access
In fulfillment of the federal SAFE Mortgage Licensing Act of of 2008, the NMLS launched NMLS Consumer Access, which
is a sanctioned, fully searchable site that allows the public to view information regarding state-licensed companies,
branches, and individuals.
The information platform has served as the bread and butter of the financial services industry
for years, and continues to grow to this day. With information on thousands of loan officers and mortgage brokers, web scraping
NMLS Consumer Access has propelled our clients to new heights and opportunities.
Data Fields:
- First Name
- Last Name
- Company
- Branch
- Individual ID
- Company ID
- Branch ID
- Address
- City
- State
- Zip Code
- Telephone
- Fax
- Website
- License
- Start Date
- Past Employment
+ Web Crawling + Web Scraping + Web Browser Automation
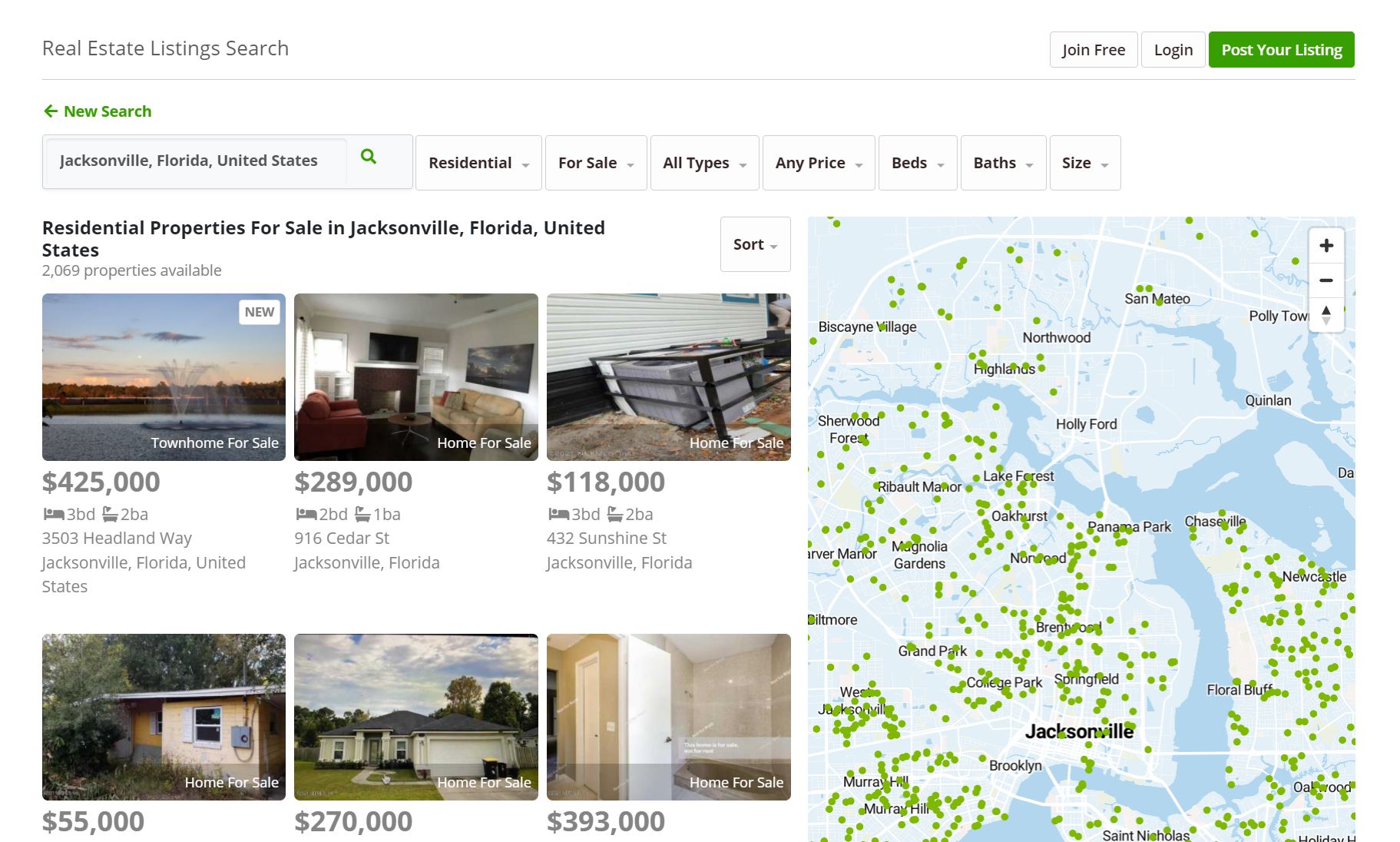
MLS Listings
Everyone is talking about the housing market. No longer do we live in a world where real estate is
a recreation exclusively for those considered "business-savvy". With information just a click away, the once casual spectator has transformed into
a miniature real estate mogul.
MLS.com is one of real estate's most trusted listing sites, notably as a result of its ability to maintain updated and detailed listings.
It also contains additional property data and contact information that would not be available on other public sites.
Without a doubt, MLS.com helps real estate agents provide the best experience for their clients.
Spidey Scrape understands the benefits that these MLS listings serve; and as a result have have worked hand-in-hand with
real estate agents to scrape and apply the data, whether it be by connecting their clients with catered listings sent directly to their email or by conducting individual research on the current housing dyanamics of certain areas.
With more than 50% of prospective home buyers conducting their searches on the internet,
it is important for real estate agents to form an understanding of how to take advantage of the massive amounts of data stored on MLS. Web scraping MLS.com, and other similar sites, such as Realtor.com, Trulia, Zillow, FSBO, and Foreclosure.com, Coldwell Banker, Compass, and Century 21, could help materialize your business model into a limitless ceiling of financial gains.
Data Fields:
- MLS ID
- Broker
- Price
- Address
- Bedrooms
- Bathrooms
- Square Footage
- Lot Size
- List Date
- HOA Fees
- Year Built
- Property History
- Noise Level
- Flood Factor
- Schools
- Home Value
- Garages
- Pool
- Style
- House Type
- Roof
- Flooring
- Appliances
- Taxes
+ Web Crawling + Web Scraping + API + Data Analytics

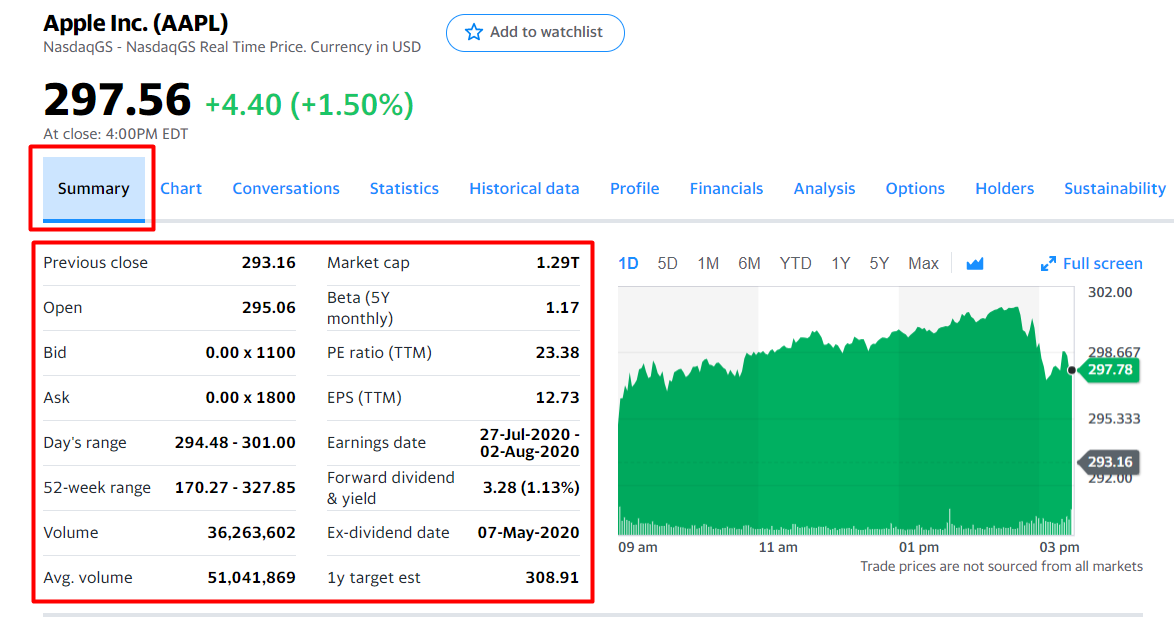
Yahoo Finance
With stocks growing in popularity over the past few years, availability of information has
become an important staple in the trading world. From day traders to position traders to technical traders,
every one of them has to leverage data in some sort of way to become successful. Yahoo Finance is one of the
most visited sites in the world when it comes to stocks. It manifests data that is positively instrumental in
explaining the general direction and patterns of price movements.
Yahoo Finance accomadates its users with access to
historical prices, summary data, earnings records, technical recommendations, risk scores, financials, price targets,
charts, and news articles. With dozens upon dozens of these data points capable of being scraped, it offers the client
the opportunity to have readily available data at their immediate disposal.
Custom scripts or APIs can be requested in order
to account for the need to constantly update data values. A Discord bot could also be reasonably implemented. Yahoo Finance is just
one of numerous credible stock sites. Other stock platforms are most certainly capable of being scraped.
Data Fields:
- Company
- Stock Ticker
- Datetime
- Price
- Open
- Close
- High
- Low
- 52-Week Range
- Market Cap
- Volume
- Beta
- PE Ratio
- EPS
- 1-Year Price Target
- ESG Risk Score
- Advice
- News Links
- Income Statement
- Balance Sheet
- Cash Flow
+ Web Scraping + Database Management + API
AAJ Lawyer PDF Directory
Contact directories are not always listed online. Oftentimes they are recorded and itemized on typed documents, such as PDF and TXT files.
While somewhat discouraging at first glance, it is important to remember that this document-based data can still be easily extracted.
Document extraction does not count as web scraping since there is no source code behind the data, but nevertheless,
the results yielded will be the same.
The American Association for Justice is among the most reputable
lawyer directories in the country. While the AAJ does possess an online directory, not every user has access to this paid membership feature. The client who requested this
work was one of those people. However, they did possess various PDF docs with all the necessary information attached to it.
Through the implementation of document-to-text extraction techniques,
all the data situated within the AAJ PDF directory docs was seamlessly transferred to a spreadsheet in a clean and organized format. The data acquired by the user with access to the online directory was
no different than that of the user with just the PDF docs. Only difference is that one person paid for access to the online directory while the other did not.
Data Fields:
- First Name
- Last Name
- Firm
- Address
- City
- State
- Zip Code
- Telephone
- Fax
- Website
- Admission Year
+ Document Extraction

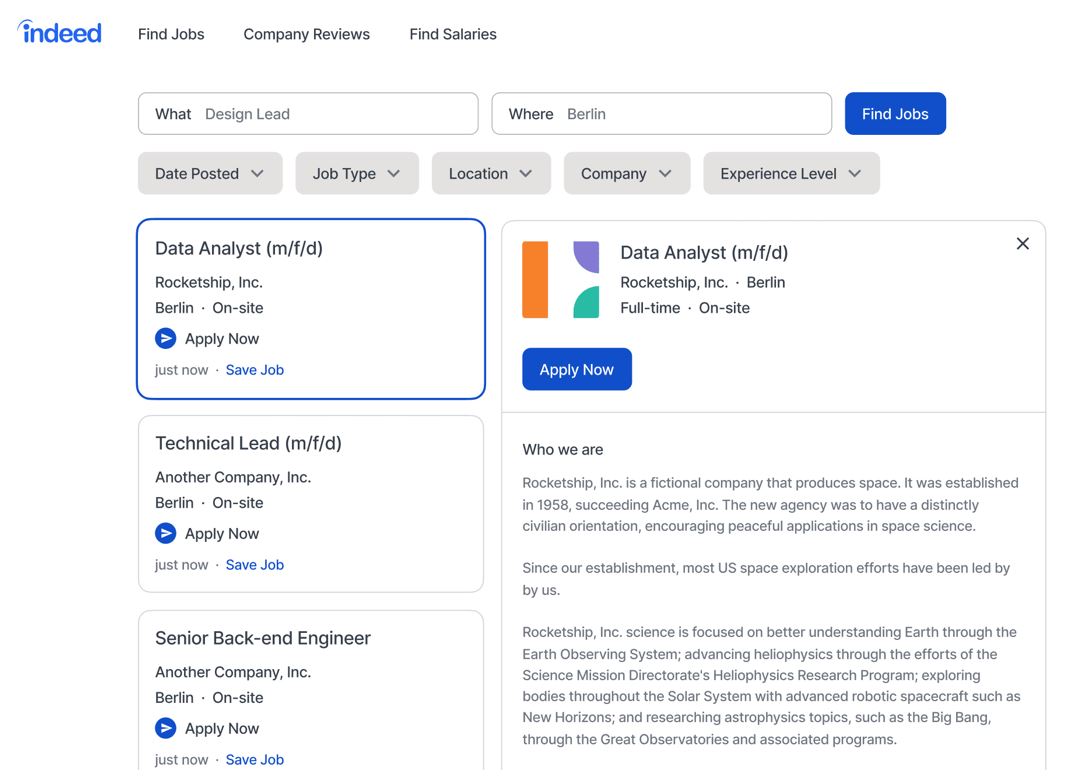
Indeed Job Postings
Whether demand for labor is high or low, the job market will always be categorized as a roller coaster ride. Over the past decade or so, Indeed
has become the principal job board site for finding talent or finding a job. Millions of users flock the site everyday in hopes of finally acquiring the
job they so desperately need. . . only to discover job postings that do not align with their skills; or job postings that have hundreds (or even thousands) of people
already applied.
By scraping Indeed job postings, Spidey Scrape was able to filter out the junk that had nothing to do with the person applying, and was able to create an organized
list of jobs for the job seeker to efficiently go through.
However, to further increase the chances of receiving interview requests,
Spidey Scrape is currently in the Beta testing phase of creating a bot that automatically applies to jobs on behalf of the prospective job seeker.
This approach will save hundreds of hours and yield better results.
+ Web Scraping + Web Browser Automation + Web Crawling

Mortgage Credit Risk Analysis
Mortgage loans are one of the most important loans that any person will ever take out during the natural progression of their life.
It is the loan that assures people of having a roof over their heads at night. And it is the loan that allows the housing market to prosper.
It would only be reasonable to assume that the risk taken on by issuing these loans should be minimized.
Extreme risk was one of the principal components that led to the
collapse of the financial markets in 2008, with approximately 1.2 million people defaulting on their loans. Assuring oneself that a loan being made is of low risk is of the
utmost importance.
Spidey Scrape had the extreme pleasure of working hand-in-hand with a premier mortgage lender to ensure that their in-house criteria for securing a mortgage loan was
suitable so as to minimize default risk.
It is projected that as the mortgage loans begin to mature in the years to come, the default rate of our client's borrowers will
gradually decrease by approximately 6.1%- this all the while hedging against any loss to potential gains in interest earned. At the end of the day, defaulted loans just create more headaches for lenders and the borrowers.
+ Data Analytics + Data Mining + Predictive Forecasting
Clothing Clearance Deals
There's absolutely nothing better than getting that cute dress you wanted for half the price. Having scraped the online clearance sections of Nike, Levi's, Marshall's, Famous Footwear, Poshmark, and Hollister, among others, Spidey Scrape has provided thifters and flippers with a spectacular opportunity to find clothing's best deals at a moment's notice.
Data Fields:
- Store
- Product
- Type
- Brand
- Discount Price
- Original Price
- Discount Rate
- Product Link
- Image Link
+ Web Scraping + API
Project Ideas
We understand that you understand the importance of our world-class services. But sometimes knowing exactly how to take advantage of these services can be frustrating. What should you do? What could you do? Here are some cool project ideas!
Streamline CRM
Automate necessary but repetitive, manual tasks in CRM to streamline processes and productivity. Sync the records from the ERP system to the CRM software to trigger automated notices. Automate the input of customer quotes, order tracking, and shipment tracking.

NBA Game Predictions
Web scrape Basketball Reference to train a model that predicts the outcome of NBA games. Integrate moneyline, spread, over/under betting strategies along with your predictions.
Theme Park Equity Research
Apply document extraction to Disney and Universal PDF financial reports to then conduct analysis on how the companies are evolving financially.
SEO Monitoring
Extract meta tags and title tags of websites that pop up when searching for targetted keywords. Find best combination of keywords and apply it to your websites.
Cargo Tracking Periodic Report Preparation
Automate periodic reporting showing times and locations where disposable GPS trackers exhibited connectivity issues and/or power outages.

Buy Low. Airbnb High.
Web scrape Airbnb to find most fruitful areas to rent out. Web scrape realty databases to discover value in locally-listed properties so that the blossoming Airbnb opportunities can be taken advantage of.

Expedia Hotel Pricing Analysis
Web scrape Expedia to train a model that predicts price and value based off the various features that the hotels offer.

Claims Processing
Reconcile and verify claims data. Copy and enter data from one system to another. Scan data from claims PDFs. Use workflow automation with a set of rules for fully automated processes.

State Employee Directory
Web scrape state government employee directories. Information would include first name, last name, email address, phone number, and agency. This information can also be cross-referenced with salary data.

Financial Customer-Product Pairing
Leverage customer profiles to cater product and service offerings. Train models to predict the probability that select customers will register for certain products and/or services based on their current profile. Young adults may be more privy to student loans. Senior citizens may have more interest in reverse mortgages. 30 year olds may be more intrigued by mortgages.

Corporate Restaurant Directory
Web scrape Dun & Bradstreet to extract corporate contact information for restaurants and eatery places. Information would include the name of the company, company description, principal contact name, address, phone number, website, corporate employee count, total employee count, year of origin, and revenue.

Amazon Competitor Price Research
Web scrape Amazon to scope out the competitive landscape and apply solutions that can correspondingly be used to gain an edge. Amazon product data can help concentrate on competitor price research, real-time cost monitoring and seasonal shifts in order to provide consumers with better product offers. Extracted information would include product name, product url, price, rating, review count, product image, product details, brand name, and ASIN code.
Frequently Asked Questions
F.A.Q.
What is web scraping?
Web scraping is the process of collecting structured web data in an automated fashion. Some of the main use cases of web scraping include price monitoring, price intelligence, news monitoring, lead generation, and market research among many others. In general, web data extraction is used by people and businesses who want to make use of the vast amount of publicly available web data to make smarter decisions.
Is web scraping scraping legal?
In layman's terms, the action of web scraping isn't illegal. However there are some rules that need to be followed. For example, web scraping becomes illegal when non-publicly available data becomes extracted. Read about the best practices for web scraping by Zyte.
What is the difference between web scraping and web crawling?
Web scraping is about extracting the data from one or more websites, while web crawling is about finding URLs or links on the web.
What is a robots.txt file?
robots.txt is a text file that is used by websites to let crawlers, bots or spiders know if and how a website should be crawled as specified by the website owner. Many sites might not allow crawling or might limit extraction from them. It is critical to understand the robots.txt file in order to prevent getting banned or blacklisted while scraping.
Do I have to know coding to use web scraping?
Nope. While coders definitely have an edge in web scraping, there are tons of tools and platforms that allow even a novice scraper to gather the data they need. Or you could just come to us. Spidey Scrape will gladly handle all the coding while you sit back with margarita in hand waiting for the data to arrive.
Are there ways to avoid getting banned or blacklisted while web scraping?
Site administrators are not always pleased when others are scraping their data. So often they will implement anti-scraping measures that block and blacklist certain users from accessing the site. However, there are several techniques that can be used to avoid getting banned and blacklisted. These techniques include using headless browsers, IP rotation, setting random intervals in between requests, setting a real user agent, scraping data out of the google cache, avoiding honeypot traps, and setting custom request headers.
Can any website be scraped?
Theoretically speaking, any website can be scraped given that the programmer performing the action is an expert. However, there are inherent legal ramifications that prohibit certain websites from being crawled and/or scraped.
Can we web scrape sites with captchas and IP blocks?
Web scrapers often get discouraged at the sight of captchas and other well-defined security measures. We are here to tell you that we have the knowledge and expertise to circumvent these obstacles. Even bots today can bypass security measures meant to stop bots.
Can Spidey Scrape teach me how to web scrape?
Of course! The world is becoming more technology-driven and Spidey Scrape wants to help everyone join the movement. Our specialization in data consulting comes with the ability to teach. Schedule private coding sessions with us today. Or, for self-learners, we provide a comprehensive written tutorial that covers all the basics of web scraping. We will also gladly provide you with external recommendations if you want to take your web scraping knowledge to the next level.
How long does it take to get your scraped data?
It will be exponentially faster than if you were to pay someone to manually enter the data. But regarding the actual scraping schematics, the speed all depends on the amount of data there is to be scraped, the mechanics of the source code, and the security measures protecting that source code. Evidently, a static website with 20,000 rows of data with no security measures will be scraped much faster compared to that of a dynamic website with 300,000 rows with captchas, IP blocks, and honeypot traps.
Contact Us
Spidey Scrape
We are a superstar squad of talented programmers who scrape data, who analyze data, and who win with data.

Mailing Address
13727 SW 152nd Street #1129
Miami, FL 33177
info@spideyscrape.com
+1 (954)408-9840